Running Tesseract
In this section, we will discuss how to install and run tesseract using the built-in language-package provided by Tesseract
Installation
To have your PC ready to run and train Tesseract we need to install few things
Cygwin
tesseract-ocr can run both in Linux and windows. But most of the documentation online is written for Linux operating system. So the best way is to use Linux or install Cygwin on a Windows machine.
Download Cygwin and install it on your machine. During the installation step, Cygwin will ask you what packages you want to install. Choose for tesseract as shown below.
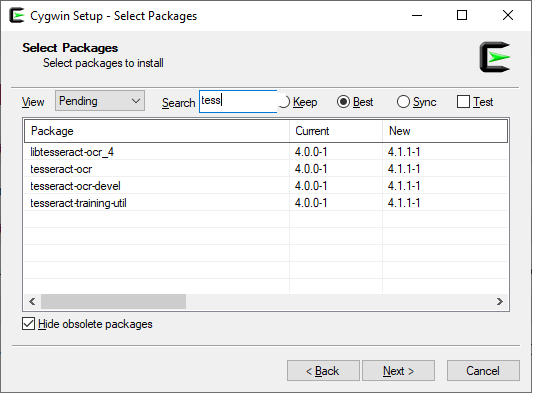 |
|---|
| Cygwin package selection |
If you forget to add tesseract, or you already have Cygwin and now you want to add tesseract, you can run the setup.exe again and add packages the same way as above.
Box Editor
A separate box editor is required to train Tesseract. One such an editor is Qt-box-editor In the training section, you will read more on how to use the box editor. Fill free to experiment with other box editors too.
Tigrinya language pack
Tesseract comes with English as a default language. During the installation process, we have to download Tigrinya language pack separately. in Tesseract tessdata repository there is a file called tir.traineddata. tir is tesseract’s language code for Tigrinya. we need to save this file into tesseract language pack directory (/usr/share/tessdata/). If you run the following command from within cygwin terminal, you will have tir.traineddata in /usr/share/tessdata/
wget https://github.com/tesseract-ocr/tessdata/blob/master/tir.traineddata -P /usr/share/tessdata/
Once you put the file in the correct folder run the following command to confirm to Tesseract where the language pack is:
export TESSDATA_PREFIX=/usr/share/tessdata
Run Tesseract
Now we are ready to run OCR on Tigrinya document. The command is as follows:
tesseract -l [language name] [input file name] [output file name]
Make a one-page jpg or tif formatted image containing Tigrinya text. Save it as ‘page01.tif’ and run the following command:
tesseract -l tir page01.tif output01
The outputo1.txt file will be created by Tesseract and it will contain the editable text version of the scanned document. The text file will not be 100% accurate. But it will give a decent output depending on the quality of the scanned image.
In the next section, we will see how to train Tesseract. With more training Tesseract will improve its ability to recognize Tigrinya characters better.