Training Tesseract
As discussed earlier the Tigrinya language-package that comes with Tesseract is descent. People can still use it AS IS with a bit of manual correction, you can have your scanned image into an editable format. However for bigger documents, where you can not manually correct each page one by one. Such approach is not feasible. A more practical and permanent solution is to train Tesseract with more sample documents and make it recognize Tigrinya characters more accurately.
A more comprehensive documentation of Training Tesseract is available at Tessract Doc. We also find this tutorial useful quick start doc. In this section we will quickly show the commands and files we use to train Tesseract for Tigrinya
The final goal for this exercise is to generate tir.traineddata file (the language-package for Tigrinya) which can later be loaded to Tesseract, so it can recognize more characters the way we want it.
Generate box file
First we need to run tesseract to generate a ‘box’ file. To do that - rename our test (or experiment) file according to the Tesseract experiment file naming convention, which is [language name].[font name].exp[number].[file extension]. In our case we are using Abyssinica_SIL font, and our file will be named tir.Abyssinica_SIL.exp1.tif
tesseract -l tir tir.Abyssinica_SIL.exp1.tif tir.Abyssinica_SIL.exp1 batch.nochop makebox
This will produce a file called tir.Abyssinica_SIL.exp1.box
Edit Box file
Open the box file using QT Box Editor. You should see something like the image below.
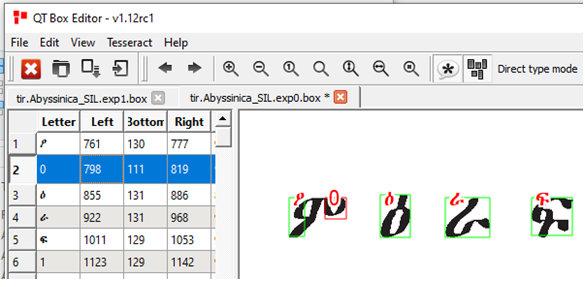 |
|---|
| Box file before editing |
The editor show all the Letters on the left side. Each letter has its own box (defined by the left, bottom, right and bottom coordinates). On the right side the image is displayed along with the box in green border. In this example we can see that ዕ,ራ,ፍ are correctly identified, however ም is recognized as ዖ and o. We can correct this by removing the box that has ‘o’, replacing ዖ with ም and stretching the first box to cover the entire ም as shown below.
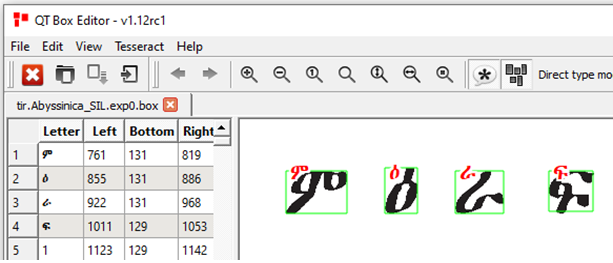 |
|---|
| Box file after editing |
By doing this, we are preparing a training file for Tesseract, next time tesseract finds an image that looks like this, it will convert it to ም instead of ዖo. It is now time to feed the modified box file back to Tesseract and generate few more files. First lets generate a character set definition and shape table.
Generating training files
Get one page tif image that contain a Tigrinya characters. Name it tir.Abyssinica_SIL.exp1.tif and un the following commands using ‘box.train’ flag to create the .tr file.
tesseract -l tir tir.Abyssinica_SIL.exp1.tif tir.Abyssinica_SIL.exp1 nobatch box.train
Then we are going to extract the charset from the box files. Before creating unicharset file we have make sure that we have the proper *.unicharset file in our working directory. In our case we need Ethiopic.unicharset and Latin.unicharset. Download both files from Here. The command to create ‘unichrset’ file is
unicharset_extractor.exe tir.Abyssinica_SIL.exp1.box
Check if we have correct unicharset file: Example of wrong unichrset file:
56
NULL 0 Common 0
Joined 7 0,255,0,255,0,0,0,0,0,0 Latin 1 0 1 Joined # Joined [4a 6f 69 6e 65 64 ]a
|Broken|0|1 15 0,255,0,255,0,0,0,0,0,0 Common 2 10 2 |Broken|0|1 # Broken
ኣ 1 0,255,0,255,0,0,0,0,0,0 Ethiopic 3 0 3 ኣ # ኣ [12a3 ]x
9 8 0,255,0,255,0,0,0,0,0,0 Common 4 2 4 9 # 9 [39 ]0
6 8 0,255,0,255,0,0,0,0,0,0 Common 5 2 5 6 # 6 [36 ]0
4 8 0,255,0,255,0,0,0,0,0,0 Common 6 2 6 4 # 4 [34 ]0
2 8 0,255,0,255,0,0,0,0,0,0 Common 7 2 7 2 # 2 [32 ]0
0 8 0,255,0,255,0,0,0,0,0,0 Common 8 2 8 0 # 0 [30 ]0
7 8 0,255,0,255,0,0,0,0,0,0 Common 9 2 9 7 # 7 [37 ]0
:
Example of correct unichrset file:
56
NULL 0 NULL 0
Joined 7 0,69,188,255,486,1218,0,30,486,1188 Latin 1 0 1 Joined # Joined [4a 6f 69 6e 65 64 ]a
|Broken|0|1 15 0,69,186,255,892,2138,0,80,892,2058 Common 2 10 2 |Broken|0|1 # Broken
ኣ 1 62,66,249,255,161,165,11,14,185,188 Ethiopic 3 0 3 ኣ # ኣ [12a3 ]x
9 8 60,64,251,255,132,142,7,11,158,161 Common 4 2 4 9 # 9 [39 ]0
6 8 62,64,251,255,132,142,9,11,158,161 Common 5 2 5 6 # 6 [36 ]0
4 8 64,66,244,255,139,149,2,8,158,161 Common 6 2 6 4 # 4 [34 ]0
2 8 64,66,251,255,128,147,7,11,158,161 Common 7 2 7 2 # 2 [32 ]0
0 8 62,62,251,255,130,147,7,11,158,161 Common 8 2 8 0 # 0 [30 ]0
7 8 62,64,247,255,121,140,4,15,158,161 Common 9 2 9 7 # 7 [37 ]0
:
If we get wrong unicharset file run the following command to correct it:
set_unicharset_properties --U unicharset --script_dir . --O unicharset
To tell Tesseract informations about the font, create font properties file (tir.font_properties) and put the followig line in the file and save it
tir.Abissinica_SIL 0 0 0 1 0
Alternatively, run the followig command to create the file and update its content:
echo "tir.Abissinica_SIL 0 0 0 1 0" > tir.font_properties
Run the following commands source
i. Run ‘shapeclustering’ - shape clustering training for Tesseract. ‘shapeclustering’ takes extracted feature .tr files (generated by ‘tesseract’ run in a special mode from box files) and produces a file shapetable and an enhanced unicharset. This program is still experimental, and is not required (yet) for training Tesseract. It creates ‘shapetable’ file. The synopsis is as follows:
shapeclustering -D output_dir -U unicharset -O mfunicharset -F font_props -X xheights FILE...
Where: -U FILE: The unicharset generated by unicharset_extractor. -D dir: Directory to write output files to. -F font_properties_file: (Input) font properties file, where each line is of the following form, where each field other than the font name is 0 or 1:’font_name’ ‘italic’ ‘bold’ ‘fixed_pitch’ ‘serif’ ‘fraktur’ -X xheights_file: (Input) x heights file, each line is of the following form, where xheight is calculated as the pixel x height of a character drawn at 32pt on 300 dpi. [ That is, if base x height + ascenders + descenders = 133, how much is x height? ] ‘font_name’ ‘xheight’ -O FILE: The output unicharset that will be given to combine_tessdata(1).
So our command will be as follows:
shapeclustering -F tir.font_properties -U unicharset tir.Abyssinica_SIL.exp1.tr
ii. Run ‘mftraining’ - feature training for Tesseract. mftraining takes a list of .tr files, from which it generates the files inttemp (the shape prototypes), shapetable, and pffmtable (the number of expected features for each character). (A fourth file called Microfeat is also written by this program, but it is not used.) The synopsis is as follows:
mftraining -U unicharset -O lang.unicharset FILE...
Where: -U FILE: The unicharset generated by unicharset_extractor. -F font_properties_file: (Input) font properties file, where each line is of the following form, where each field other than the font name is 0 or 1:’font_name’ ‘italic’ ‘bold’ ‘fixed_pitch’ ‘serif’ ‘fraktur’ -X xheights_file: (Input) x heights file, each line is of the following form, where xheight is calculated as the pixel x height of a character drawn at 32pt on 300 dpi. [ That is, if base x height + ascenders + descenders = 133, how much is x height? ] ‘font_name’ ‘xheight’ -D dir: Directory to write output files to. -O FILE: The output unicharset that will be given to combine_tessdata(1).
So our command will be as follows:
mftraining -F tir.font_properties -U unicharset -O tir.unicharset tir.Abyssinica_SIL.exp1.tr
This command creates the following files: pffmtable, inttemp and tir.unicharset
iii. Run ‘cntraining’ - character normalization training for Tesseract. ‘cntraining’ takes a list of .tr files, from which it generates the normproto data file (the character normalization sensitivity prototypes). The synopsis is as follows:
cntraining [-D dir] FILE...
Where dir is an optional which is directory to write output files to.
cntraining tir.Abyssinica_SIL.exp1.tr
This command creates normproto file.
iv. Rename files Now rename all files created by mftrainig and cntraining (add the prefix tir)
mv inttemp tir.inttemp
mv normproto tir.normproto
mv pffmtable tir.pffmtable
mv shapetable tir.shapetable
v. Create tir.traineddata file Finally combine tessdata using the following command
combine_tessdata tir
This command creates the tir.traineddata file.